重磅发布:aiXcoder-7B正式开源
4月9日,aiXcoder推出全新自研7B代码大模型。该模型在多个主流评估标准评测集中,与所有同量级开源模型对比效果最佳,彰显出其作为百亿参数天花板级代码大模型的非凡实力。
从评测集综合结果来看,aiXcoder-7B相较于传统的刷题式代码生成,它专门针对企业级软件项目,在真实开发场景下效果出众,这意味着aiXcoder-7B非常适合企业私有化部署。其中,aiXcoder-7B Base版开源共享给开发者,并陆续在 Github、Gitee、Gitlink 等平台上线。
aiXcoder团队孵化自北京大学软件工程研究所,在AI与软件开发交叉领域探索已历十年,是智能化软件开发领域的开拓者,专注于企业开发场景的服务。

代码生成与补全效果达SOTA
真实场景中的编程总需要面对层出不穷的情况,而人工构造的测试集能力有限,可能会遇到规模和多样性有限、难以评估上下文理解能力、难以衡量泛化能力等问题。因此aiXcoder-7B模型选择了不同维度的测评集,全面验证模型实际能力,并指导模型迭代和应用部署。
在多个主流评估标准评测集中,无论是代码生成、代码补全还是跨文件上下文代码生成效果,aiXcoder-7B模型均有极佳表现,甚至超越参数量大5倍的34B代码大模型,已达到当前SOTA水准,堪称最适于实际编程场景的基础模型。
测评效果1:在 HumanEval(由 164道Python编程问题组成)、MBPP(由974个 Python编程问题组成)和 MultiPL-E(包含了18种编程语言)等主流代码生成效果评估测试集上,aiXcoder 7B 准确率显著超越当前同级别代码大模型。
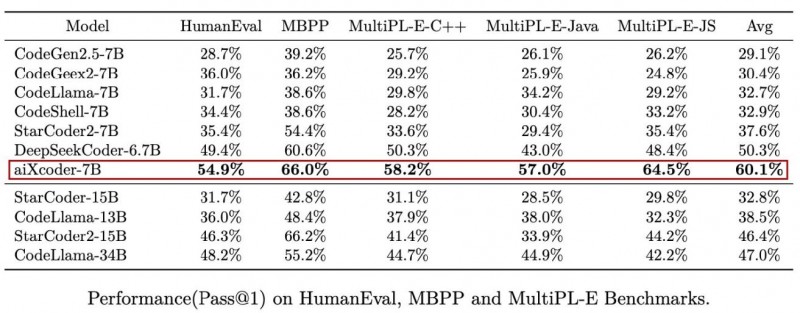
测评效果2:相对于HumanEval等测评集中的任务,真实开发场景的代码生成需要考虑当前编写代码的上下文信息。在Santacoder(Ben Allal et al., 2023) 提出的考虑上下文补全评测集上,aiXcoder-7B Base版在与 StarCoder 2、CodeLlama 7B/13B、DeepSeekCoder 7B 等主流同量级开源模型的较量中取得了综合最佳效果。
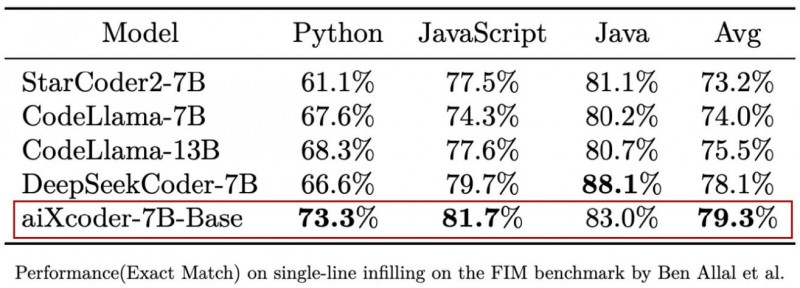
为了进一步精细地评测代码大模型在代码补全上的能力,aiXcoder 构建了一个比SantaCoder数据量更大,被测代码多样性更高、被测代码上下文长度更长、更接近实际开发项目的评测集 (16000多条来自真实开发场景的数据),在此测评集上aiXcoder-7B 同样效果最好。
同时aiXcoder-7B 表现出了相较于其他代码大模型的又一大亮点,即倾向于使用较短代码来完成用户指定的任务。在针对Java、C++、JavaScript和Python编程语言的代码补全测评时,aiXcoder 7B Base不仅效果最好,四处红框圈出的生成答案长度明显短于其他模型,并且非常接近于标准答案长度(Ref)。

测评效果3:aiXcoder-7B 在更贴近真实开发场景的跨多文件代码补全任务上同样表现极佳,在评估代码大模型提取跨文件上下文信息能力的CrossCodeEval测评集上,aiXcoder-7B 一举拿下了同级别模型的最好效果。从测评结果中看出,aiXcoder-7B在只通过光标上文搜索到的结果作为 prompt,同时其他模型拿 GroundTruth搜索到的结果作为prompt,前者的效果依然要强于后者。

在真实开发场景中,aiXcoder-7B模型具有更多优势,展现出独特的科技智能与美学。比如预训练采用32K token的上下文长度,并且推理时可扩展至256K,能覆盖整个开发项目中的绝大部分代码;可准确判断何时需要生成新代码、何时代码逻辑已完整无需补全,直接生成完整的代码块、方法体、控制流程;可以准确地抽取项目级的上下文信息,大大降低大语言模型在预测API时产生的幻觉。
高质量训练数据和针对性训练方法养成记
大模型领域流行一句话:“Garbage in,Garbage out”,即输入垃圾数据会导致输出垃圾结果,可见对大模型进行预训练,数据是重中之重。aiXcoder-7B模型的超强表现,首先得益于高质量训练数据和针对性训练方法。
aiXcoder-7B模型训练集涵盖1.2T Unique token数据,覆盖数十种主流编程语言。aiXcoder团队在构建训练数据时,针对数十种主流编程语言进行了语法分析,过滤掉错误的代码片段,还对十多种主流语言的代码进行了静态分析,总共剔除了163种bug和197种常见代码缺陷,确保了训练数据的高质量。
为了增强模型对代码语义和结构的建模能力,aiXcoder团队采取了多种创新策略。一方面利用代码聚类和函数调用关系图的方式,捕捉多个文件之间的相互注意力关系;另一方面,将抽象语法树的结构信息融入了预训练任务中,帮助模型学习代码的语法和模式特征。
总体而言,通过处理更高质量的数据,以及构造更贴近开发行为的代码大模型预训练任务,我们发现aiXcoder-7B 在考虑代码项目上下文这种更真实开发场景下,具有当前代码大模型中最佳的效果。
“开箱即适配”的企业级代码大模型
第一,易部署。在企业实际环境中部署时,通常企业的部署资源是受限的。aiXcoder-7B 只有7B参数规模,易于部署,还有成本低、性能好的优点。
第二,易定制。大多企业都有自己的软件开发框架和API的库,与其关联的业务逻辑、代码架构规范都因地制宜,十分个性化,同时这些内容又都有私密性。必须得让大模型学会这些企业代码资产,通过进行有效个性化训练,才能真正为企业所用。
第三,易组合。未来提供企业服务时,会让多个7B模型形成MoE架构,组合成为一套解决方案来完成企业定制化服务。不同的企业,都可以得到符合自身个性化需求的MoE版代码大模型解决方案,既能使用产品,又可享受服务。
个性化是企业级代码大模型在传统行业落地最大的鸿沟,aiXcoder“开箱即适配”的一站式智能解决方案,能够为企业级用户提供精准、高效、安全、连续的软件开发服务,提高项目的开发效率和代码质量。
aiXcoder代码大模型落地可靠性“闯关”成功
aiXcoder 7B通过“开源+闭源”双循环式的生态布局战略,产业反哺技术,扩大行业领跑优势。企业级专属版本针对企业级客户,通过大量的C端用户、B端开发者,会收集到更多关于通用模型的真实反馈,了解实战效果和存在的痛点,并将这些转化为模型和产品层面的优化点,快速应用到企业客户,持续深化B端产品能力和服务质量,扩大在企业级市场的渗透率。aiXcoder-7B模型具有更快、更准的优势,是其他模型效率的至少2倍,这极大降低了企业的开发成本。
十余年来,aiXcoder致力于做中国代码大模型商业化探索的先行者,引领代码企业级私有化、管理智能化。目前主营业务聚焦于代码大模型的私有化部署、个性化训练和定制化开发三大核心领域,一站式为企业客户提供定制化解决方案,专属高效服务确保应用可落地。
许多企业级客户群特别重视数据安全和隐私,代码等资产不能上传云端。如何利用有限的GPU资源达成最佳效果,成为企业私有化部署的最大痛点。aiXcoder专攻对国产AI芯片和英伟达低端显卡的模型适配,布局最早并且效果最好,无论国产硬件还是进口硬件,都能得到最佳支持和性能保障。此外,在模型训练和推理优化等方面,也为客户提供了高效、稳定的服务保障。
根据客户的业务需求,aiXcoder提供个性化的训练方式,结合企业领域知识进行个性化训练。个性化训练方案能够有效提高模型的准确率,满足客户在不同行业、不同场景下的特定需求。相较于行业其他厂商的同质化训练方案,aiXcoder基于原生大模型技术的个性化训练方案,具有更高的灵活性和针对性。
aiXcoder注重将长期服务企业所累积的行业经验和专业领域知识,融入产业实践,促成商业落地。团队多年深耕传统重点行业,对这些领域有着独到的理解,将这些专业知识与定制化开发相结合,必将让aiXcoder赋能企业代码大模型的效果事半功倍。
目前,aiXcoder已服务大量银行、证券、保险、军工、高科技、运营商、能源、交通等行业头部客户,深耕服务金融行业,其中与某头部知名证券企业的“代码大模型在证券行业的应用实践”项目荣获2023AIIA人工智能十大潜力应用案例、中国信通院AI4SE银弹优秀案例等殊荣。
探索软件自动化的征程正迈向一个前所未有的智能化时代,aiXcoder团队的每一次重大突破,都致力于打造更加智能、高效、安全、可靠的软件系统,努力成为大模型与传统软件可靠融合的重要推手。未来,我们将继续砥砺前行,持续为开发者提供更卓越的模型和服务!
本文地址://www.styjt.com/pinpai/2024-04-09/673153.html
友情提示:文章内容为作者个人观点,不代表本站立场且不构成任何建议,本站拥有对此声明的最终解释权。如果读者发现稿件侵权、失实、错误等问题,可联系我们处理
- 上一篇:V23首秀在即,iCAR品牌之夜共同见证美好即将发生
- 下一篇:返回列表



- 重磅发布:aiXcoder-7B正式开源2024-04-09 17:25:48
- V23首秀在即,iCAR品牌之夜共同见证美好即将发生2024-04-09 17:24:36
- 如何预防春季手足口病?2024-04-09 17:20:38
- 女人的晚年幸福,竟和漏尿息息相关?2024-04-09 17:12:46
- 薇琳卓悦1号:革新技术引领自然美学,塑美效果再升级2024-04-09 16:45:27


 国家食品药品监督管理局查询入口
国家食品药品监督管理局查询入口2023-05-11
 中国四大顶级医院
中国四大顶级医院2023-09-13
- 70岁以上老人核酸检测费用多少 新规定明天起不做核酸了吗
2022-11-07 17:44:38
- 十大不建议买的纯牛奶排行,不能喝牛奶的原因
2023-06-30 14:06:52
- 梅婷现任70岁老公曾剑个人资料(曾剑个人资料)
2022-09-08 09:22:36
- 烟台今天已封闭的小区 烟台现在封闭小区名单有哪些
2022-10-12 09:07:30
- 张家界桑植新娘吴梅婚纱照事件完整版 看女主出轨聊天内容视频
2022-11-11 14:27:00


文章排行榜
- 周排名
- 月排名
- 1加入云南白药健康口腔123计划 一刷一漱呵护牙龈
- 2专研中国干敏肌神经酰胺护理 花王旗下品牌“Curél珂润” 参加2024全国中西医结合皮肤性病学术年会
- 3中析生物完成Pre-A++轮融资,赛富璞鑫医疗健康投资基金独家投资
- 4《健康中国共同富裕——浙江国医堂控股集团专项推广会》圆满落幕
- 5均胜电子2023年研发投入36.5亿元 重点围绕智能驾驶、智能座舱与网联创新
- 6讯飞机器人超脑平台亮相中国人形机器人生态大会,引领智能交互新趋势
- 7新增“机器人概念” 视源股份机器人专利申请量已超600项
- 8“扬子江龙凤堂”中药品牌成功入选“江苏老字号”名录
- 9行业最强护眼电视“星光S1”系列4月6日开抢
- 10迅达全新零冷热水器,静音科技引领沐浴新时代!
